
Private database join performed by Retency delivers Differentially Private datasets which train AI models as accurately as non-private data. This page contains an example of analyses that illustrate how Retency Privacy Engine protects training of your usual AI tool.
For this, it is interesting to compare how Machine Learning models are trained in one of the two situations:
The objective is to train a predictive model providing the probability of lung cancer based on certain individual living habits. For this, it is necessary to create a training dataset that results from the line-by-line association of two databases sharing the same individual identifier:
A priori, model training would require a non-confidential a line-by-line join between the two tables.
Two AI models using the same algorithm are set up:
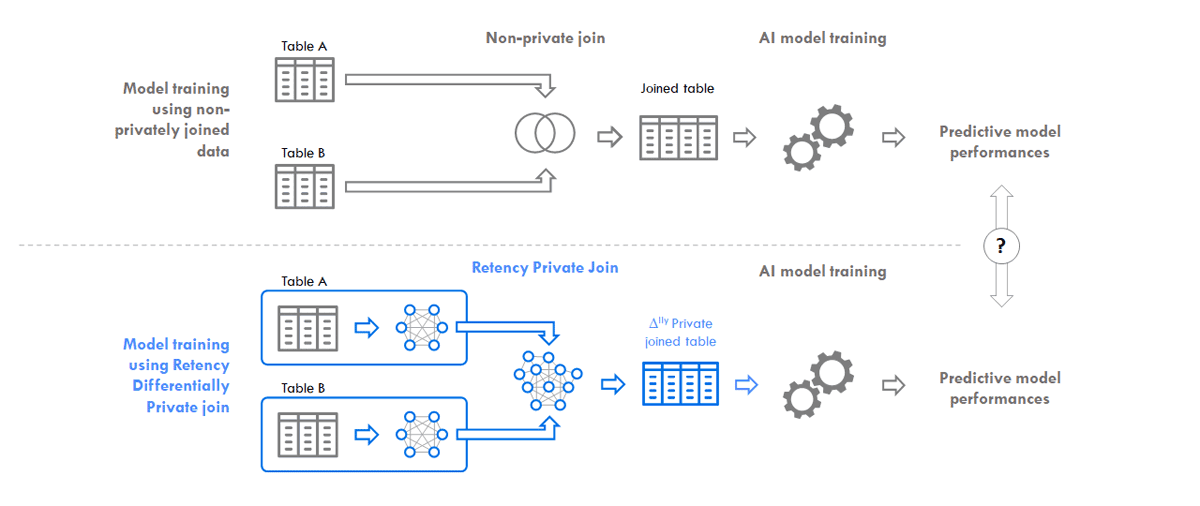
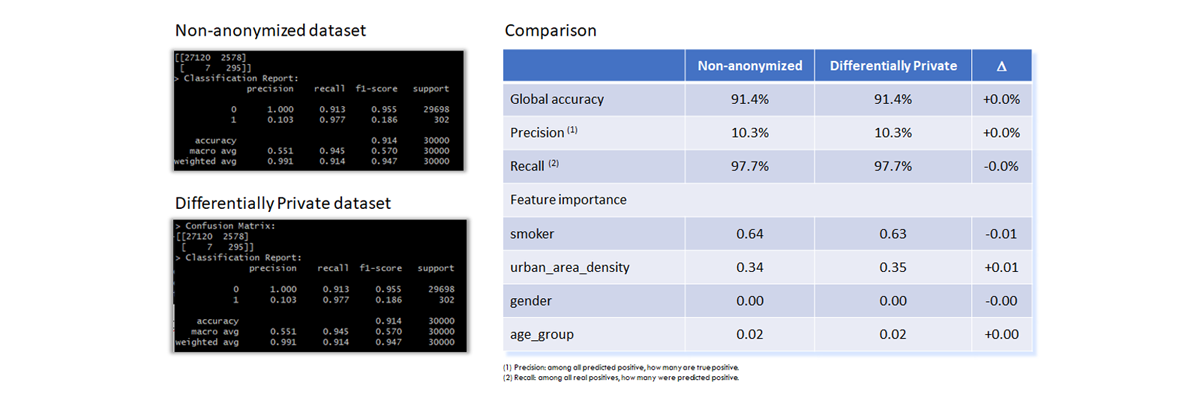
The training results for both models are compared:
The same process is performed with 3 types of machine learning algorithms: Logistic Regression, XGBoost and Random Forests.
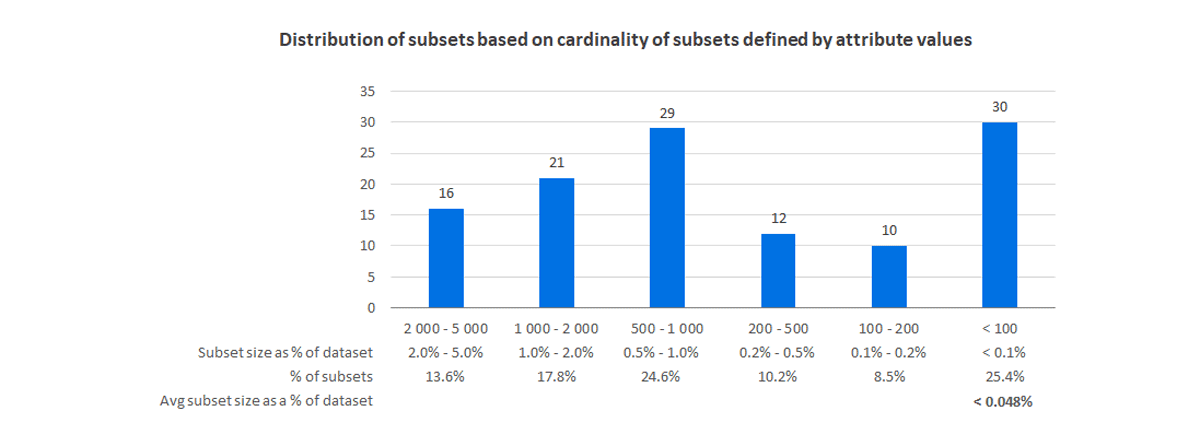
The test data contains infrequent situations that aptly test the capacity of Retency Privacy Engine to detect weak signals. The total dataset counts 100K individuals. The partition of the dataset in subsets where all individuals share the same attributes and target variable counts 121 subsets. Subset distribution by cardinality is summarized below. For instance, 25.4% of subsets contain less than 0.1% of the total population, with an average cardinal equal to 0.048% of the total population.
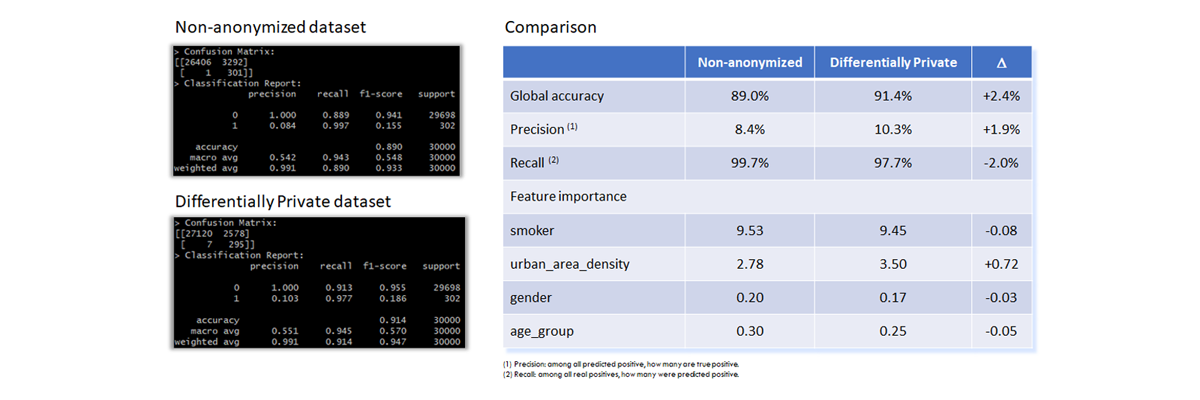
In this section, logistic regression algorithms are used. The model implementation uses scikit-learn packages in python scripts.
The table below shows the excellent correspondence between the two models in terms of performance and feature importance.
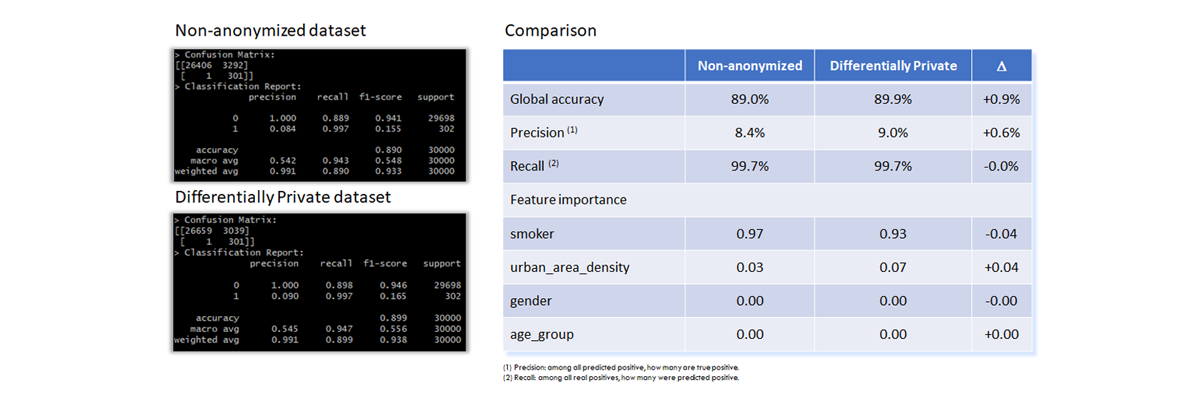
In this section, datasets educate XGBoost models. The model implementation uses scikit-learn packages in python scripts.
The table below shows the nearly-perfect correspondence between the two models in terms of performance and feature importance.
In this section, datasets educate Rand Forests models. The model implementation uses scikit-learn packages in python scripts.
The table below shows the perfect correspondence between the two models in terms of performance and feature importance.
Our company has been developing best-in-class Differential Privacy software solutions for corporate needs since 2015. We are renowned professionals of software development.
place152 bvd Haussmann - 75008 Paris France
mailcontact@retency.com
stay_current_portrait+33 1 45 20 46 85